Совсем недавно мы запустили бета-тестирование по заявкам. Решил рассказать про технические проблемы при извлечении статей, что происходит под капотом.

Предыстория
Я делаю веб с 2013 года. Начинал в те времена, когда JQuery был модным (или выходил из моды, не помню), никто особо не делил разработку на фронт и бэк, JavaScript был мерзким, а PHP приятным. В общем, трава зелёная и мозг ещё чистый от академического программирования.
Что тут интересного? Ничего, веб самая лёгкая по порогу вхождения технология. Вот тебе Body, DIV, CSS классы, пару функций JS для работы с DOM и npm. Разобрался? Ты уже почти умеешь в веб и можешь даже деньги зарабатывать.
Интересное начинается, когда из-за простоты и гибкости стандартов, веб начинают делать все, кто хотят. Только не подумайте, что я против: я сам с этого начинал.
Основное содержимое веб-страниц
Слышали когда-нибудь про Facebook Instant Article? Google AMP? Yandex Turbo? Telegram Instant View? Ну в браузерах ещё кнопка такая есть, типа Show Reader View.
Все эти технологии решают примерно одну и ту же задачу – упрощают, ускоряют и стандартизируют потребление контента на своих платформах.
Вы не покидаете приложение, когда открываете ссылку на статью, не ждёте загрузки браузера и мегабайтов зависимостей веб-страницы, короче, быстрее получаете то, что хотите.
При чём здесь эта предыстория?
Разработчики не думают, что их веб-сайты будут обрабатывать машины, максимум вставят мета-теги, типа OpenGraph, чтобы, если кто-то поделится ссылкой на страницу в условном твиттере или она появится в поисковой выдаче, отображалась нарядная картинка с заголовком и описанием.
Машина не разберётся в вашей разметке вот прямо просто так. Вы и сами не разберётесь, скорее всего, если будете читать вёрстку на одних DIV. Максимум предположите за что отвечает какой-то узел дерева.
Google, Facebook и Yandex не дурят себе голову и предлагают вам самим разобраться с вашим сайтом и отдать содержимое в нужном им формате.
С телеграмом веселее. Ничего перевёрстывать не нужно, достаточно разобраться в их расширении для XPath и написать шаблон, который занимает десяток строк. Только вот будет ли у вашей ссылки кнопка Instant View и не зря ли вы писали шаблон, решат модераторы платформы. Уточка говорит, что зря 🦆
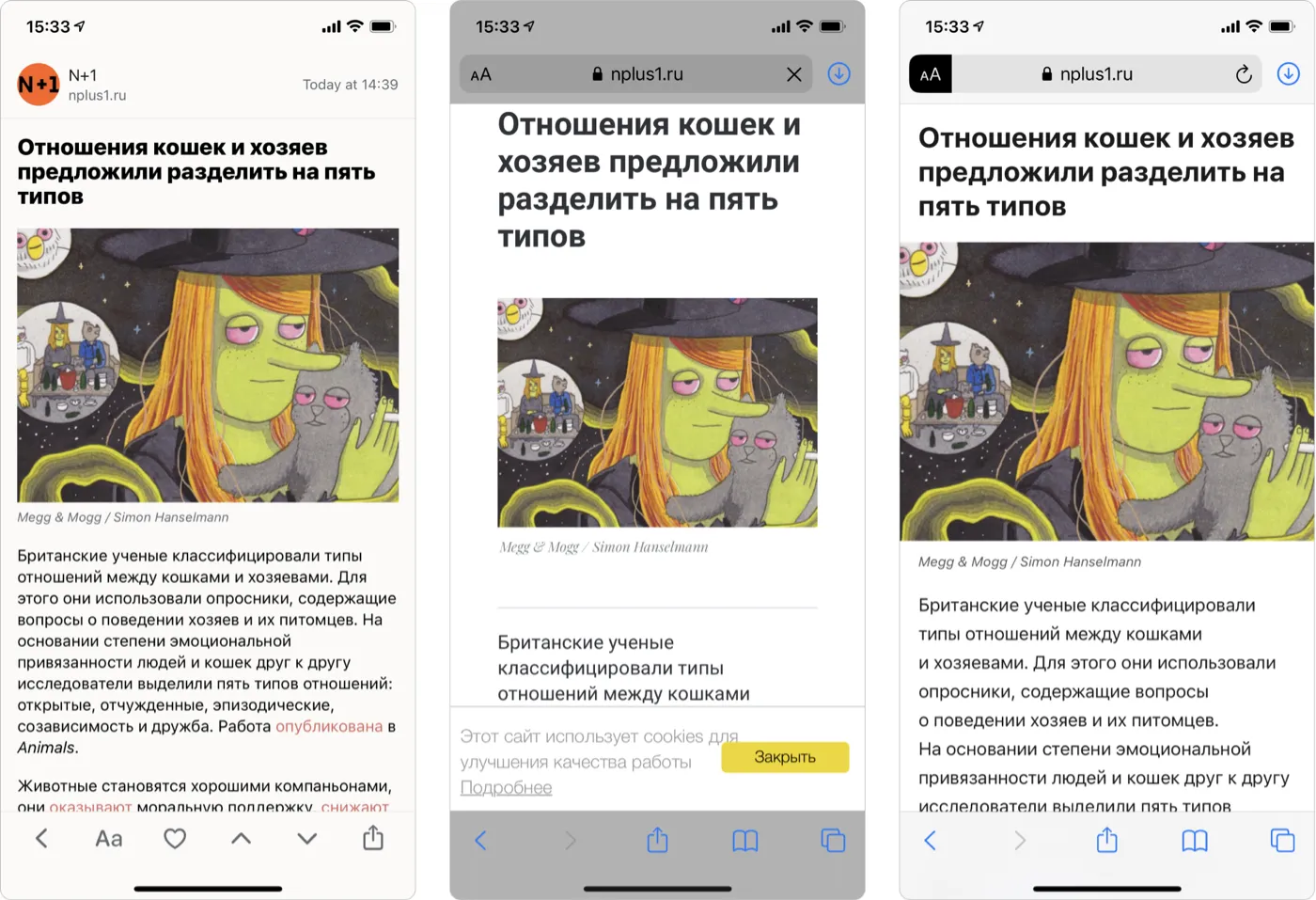
С Reader View интереснее. Исходный код оригинальной реализации в Firefox под названием Readability.js доступен любому желающему. В Safari используется его модификация, если они там ещё всё не переписали.
Но с подходами, которые применяются в Readability для поиска содержимого статей, есть небольшая проблема – они ориентируются на семантику и её уже сейчас нужно переписывать.
Как-то посчитал на паре десятков популярных новостных сайтов применение семантических элементов и “правильность” применения. Оказалось, что больше половины сайтов не использовали семантические элементы или использовали их не совсем корректно. Например, на сайте CNN в article наваливают всё содержимое от шапки до подвала.
А ещё в HTML недавно завезли прикольную штуку под названием Custom Elements. Вы можете сами определять свои собственные теги. Эту технологию можно использовать прямо сейчас. Если завтра кому-то придёт идея использовать её в крупных библиотеках, типа Vue или React, можно будет услышать громкий хруст семантической вёрстки, вы же помните про низкий порог вхождения? Readability на таких сайтах не работает, проверял.
Есть ещё машинное зрение и нейронные сети. Прикинул, как это может работать:
- хром рендерит страницу;
- некоторый модуль X просматривает страницу и возвращает координаты хрому с основным содержимым;
- хром преобразует кусок DOM дерева в этих координатах.
Звучит минимум дорого, если у тебя нет чемоданчика с баблом или проект так и останется навсегда на локальной машине.
Приложение и сервис
Мы хотели приложение, в которое можно добавлять сайты, читать статьи в нативном интерфейсе и даже получать пуши про новые. Делать это независимо от социальных сетей, поисковых систем и опубликованной ссылки в телеграм канале.
Зная проблемы существующих решений и предполагая проблемы в будущем, получился алгоритм, который умеет извлекать основное содержимое из страниц и даже не ориентируется на семантику элементов – забивайте на семантическую вёрстку дальше.
- Вся обработка происходит на стороне сервера, клиенты не пыхтят над разбором и не делают лишних HTTP запросов.
- Пользователи добавляют сайты, где есть RSS или Atom каналы. Мы поддерживаем любой сайт, который поддерживает эти технологии.
- Из RSS или Atom извлекаются только ссылки на статьи и небольшая часть метаинформации. Содержимое фидов разработчики часто режут и оставляют только анонсы, поэтому мы на них не ориентируемся.
- Метаинформация статей извлекается комбинировано из потоков, веб-страниц и содержимого статьи, если его удалось определить. Последнее слово всегда за веб-страницей.
- Содержимое извлекает полноценный браузер, которому можно скармливать даже сайты, где страницы рендерит JavaScript.
- Содержимое статей из HTML преобразуется в JSON с нормальной типизацией (абзацы, заголовки, изображения и так далее), который значительно легче исходной разметки.
- По моим замерам, статьи в Artykul в 15 раз меньше, чем исходные HTML документы.
- Алгоритм обладает эффектом “памяти”. Чем больше статей обрабатывается с веб-сайта, тем корректнее определяется основное содержимое (при условии, что оно определяется корректно в большинстве случаев).
Для владельцев сайтов и разработчиков
Если вы ведёте блог или вы владелец новостного сайта, давайте дружить. У нас есть некоторые идеи с интеграцией в нашу систему.
Например, мы можем оповещать ваших подписчиков про новые статьи. Есть варианты с более тесной интеграцией, например, счётчики комментариев и активные ссылки на них; дополнительные функции для общения с аудиторией в нашем приложении. Это, наверное, было бы полезно и вам, и вашим подписчикам. А нам интересно, что из этого может выйти.
Если вы разработчик, то у нас для вас очень простое API. Реализовать полноценный клиент, поддерживающий все методы, можно за пару часов. Ещё у нас есть кроссплатформенный клиент для просмотра статей, который можно легко кастомизировать и интегрировать в существующее приложение.
Если вам интересно, свяжитесь со мной.





Comments
To post a comment, please log in or create an account.
Sign In